一些常见的搜索引擎爬虫
对于个人网站来说,爬虫是很重要的的,爬虫可以将你网站的内容收录从而提升网站曝光率。
这里爬虫指的就是搜索引擎,因为搜索引擎本身也是爬虫。
当然,好的爬虫对网站是有益的,但是还有一些无益的爬虫,也就是有目的性的爬虫,俗称采集,一方面可能会将你的网站的内容采集到他的网站,另一方面可能会加重服务器的负担,甚至于导致服务器宕机,造成不可估量的损失。
最近看了一下笔者网站www.dsiab.com的爬虫记录,能发现一下常用的搜索引擎的爬虫痕迹,主要就是通过userAgent来判断,因为笔者的网站会将nginx的日志提取,nginx是默认记录了访问者的一些信息的,其中包括Ip,userAgent,userAgent中的信息会显示访问者用的是什么浏览器,以及一些是否为爬虫的标记。
一下为一些常用爬虫信息:
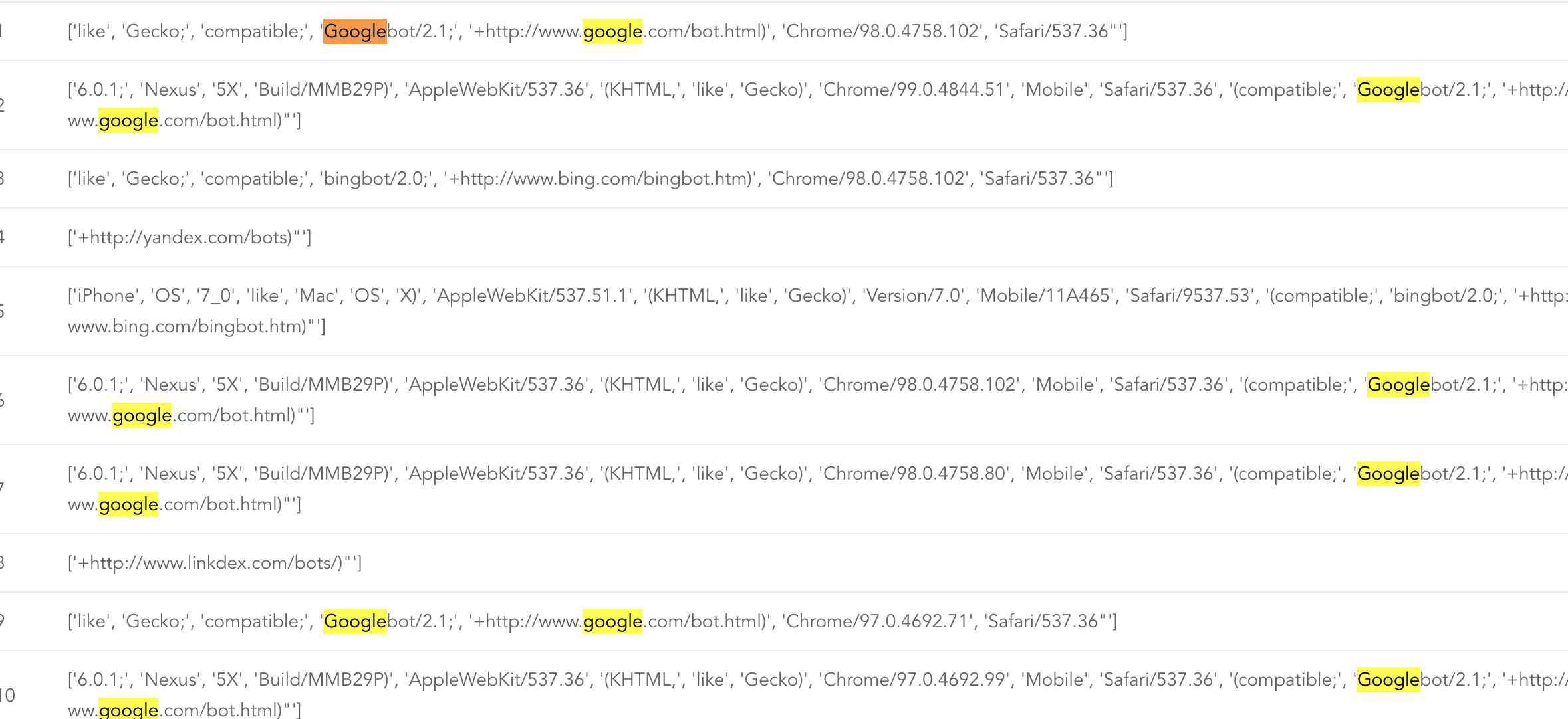
常见的谷歌、bing都有爬取,而且通过记录可以看到同一个搜索引擎的userAgent的信息可能还不一致,说明爬虫可能会伪装成不用的浏览器。
而且可以通过一个关键字bot来识别是否为搜索引擎,但是百度引擎是通过spider来识别,如果是一些不怀好意的爬虫可能就不会带这些关键字了。
对于一些采集爬虫我们可以通过nginx的黑名单来阻止爬取,具体做法就不介绍了,大家可以自行搜索添加。
当然也可用通过现在比较流行的kong网关来实现,kong网关可以添加一些插件来是实现黑名单、限流等操作。
有兴趣可以了解kong网关:https://konghq.com/
发表评论 (审核通过后显示评论):